



👋 meet qryn
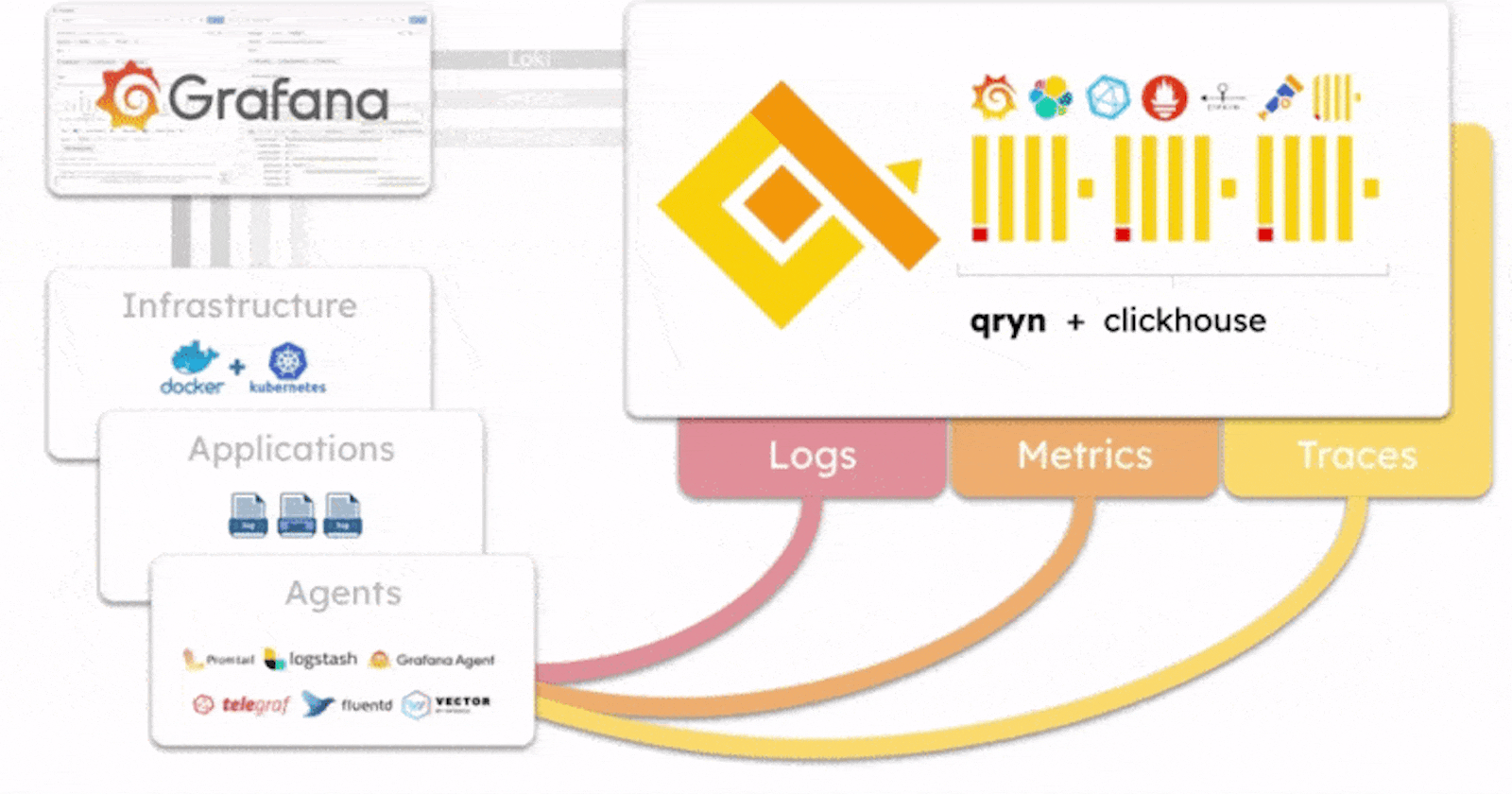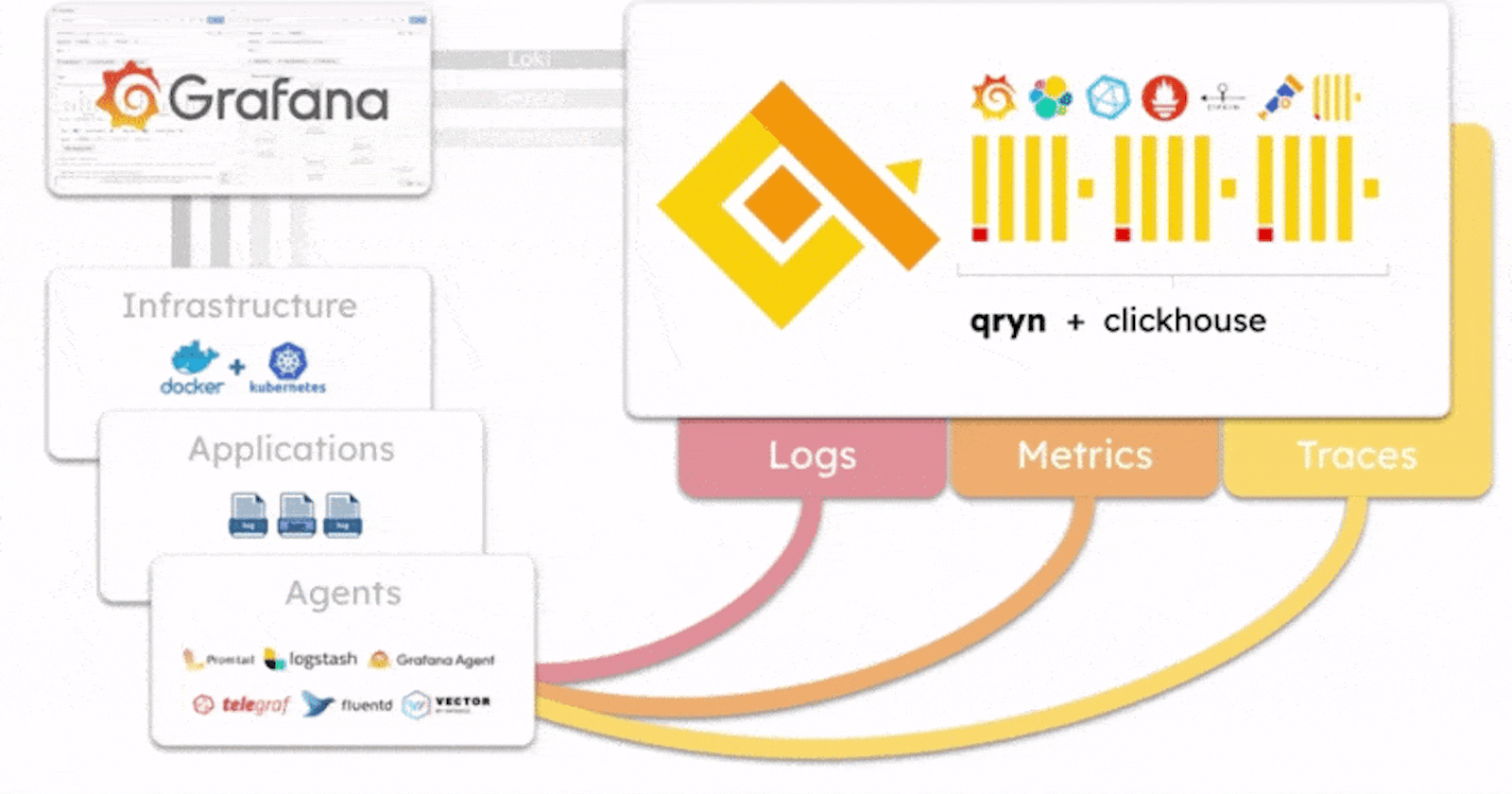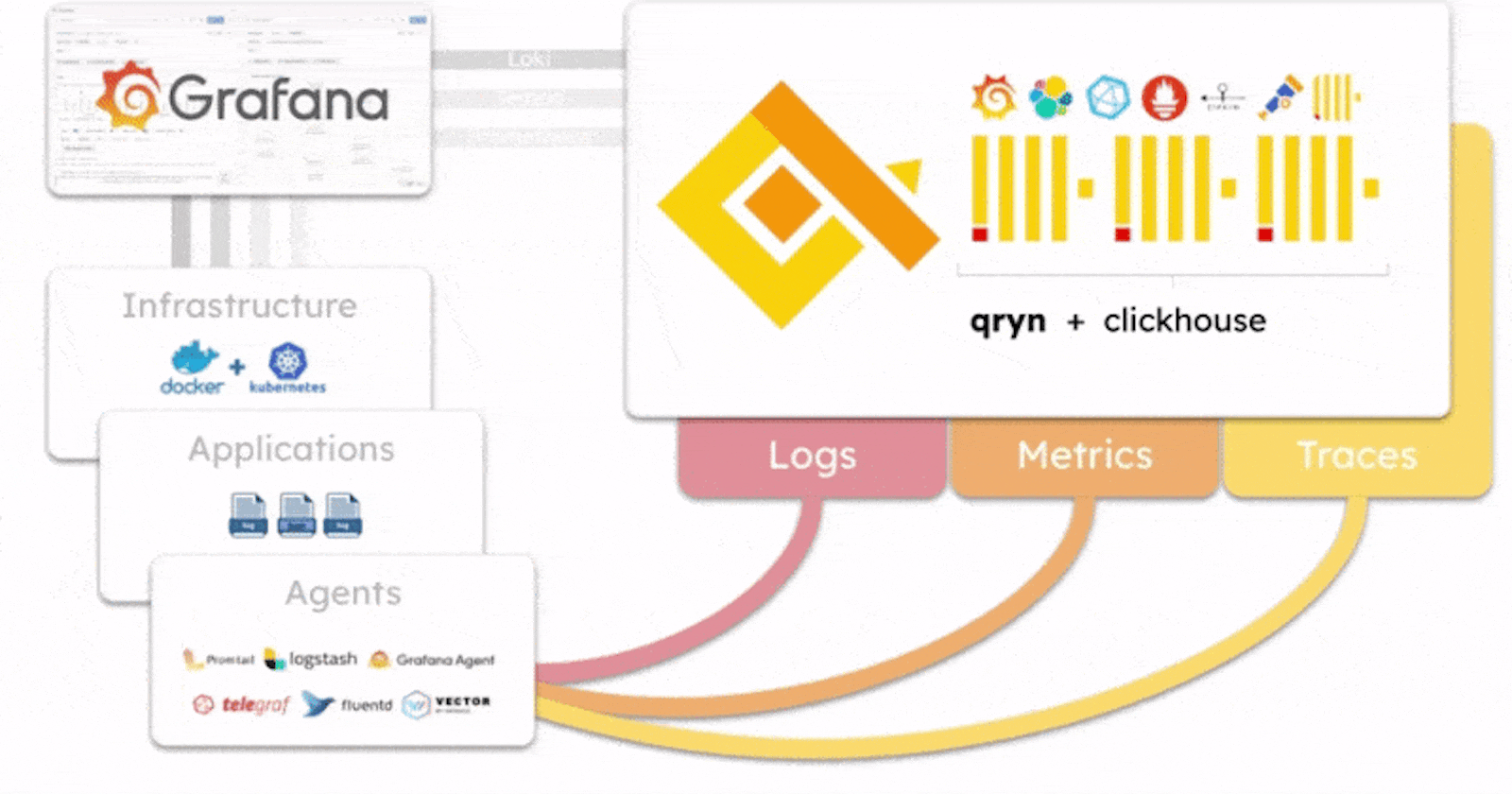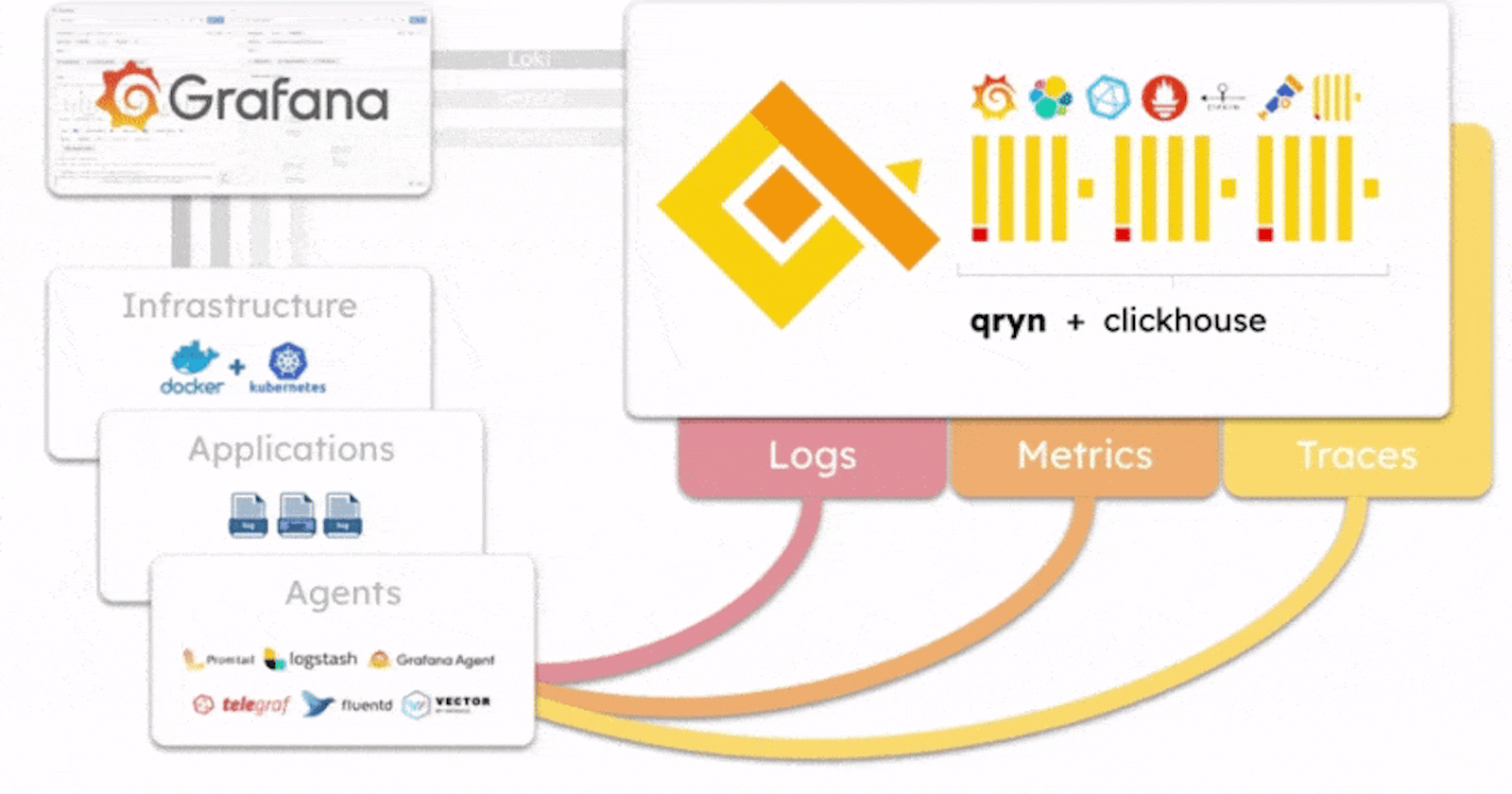
qryn is an open-source project built on the idea of polyglotism, which is the ability to speak multiple languages. This unique approach allows it to be used with a wide range of different observability solutions and data sources through a unified ingestion pipeline for industry-standard data ingestion formats (compatible with Loki, Prometheus, Elastic, Influx, OTLP, and others) efficiently handling logs, metrics and telemetry, and transparently supporting popular query languages such as LogQL, PromQL and Tempo - and more coming!
🚥 logs, metrics and tracing
You're probably familiar with these three categories of software instrumentation: logs, metrics and tracing. At the end of the day, they all represent a derivative of time series data. However, they're usually stored separately and often require different tools to process and access them. This means that we often have to deal with multiple data stores for each type of information, and often multiple data formats. A nightmare when it comes to correlation, control and compliance.
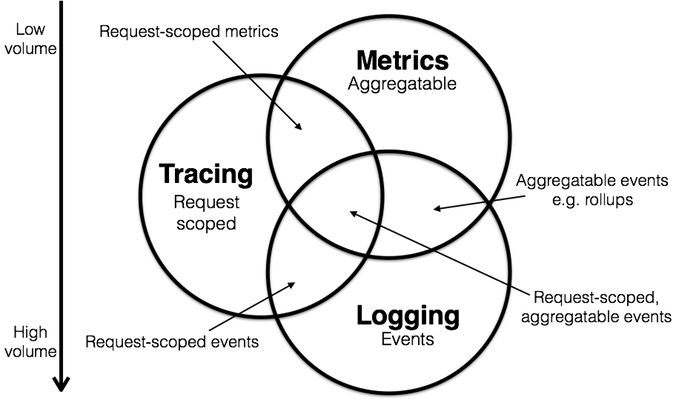
In qryn all formats are reunited with ClickHouse and automatically cross-connected and correlated out of the box - You data is instantly accessible through the numerous product integration APIs as well as directly through SQL queries for advanced users.
TLDR; One system and one database for all of your data APIs at once

It's a polyglot framework. No new formats to learn and adopt.
Unlike other observability frameworks, qryn does not come with yet another agent or format standard to collect data. Instead, our polyglot stack adopts standard API and formats natively integrated by popular agents (Vector, Telegraf, Logstash, Grafana-Agent, Promtail, etc) to collect logs, metrics, traces and time series using the same data formats as Loki, InfluxDB, Elastic or Prometheus.
You can then query those same time series in any language or tool you like.
Et voila'
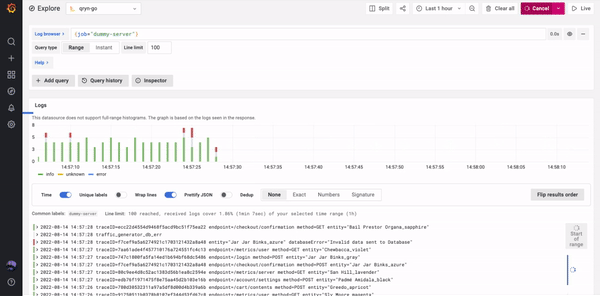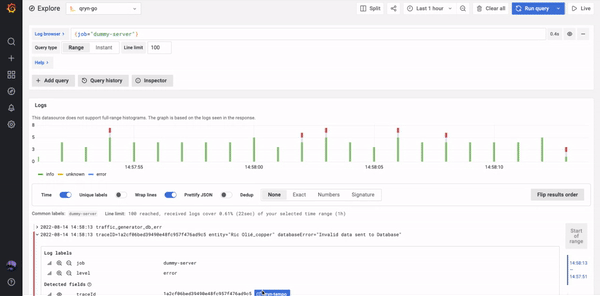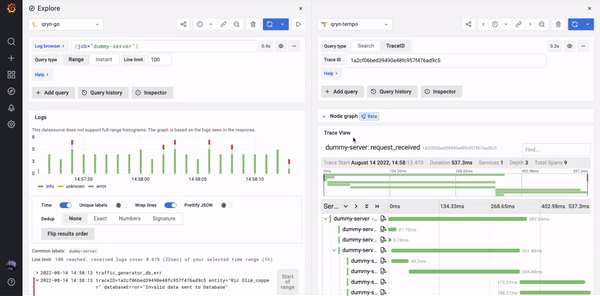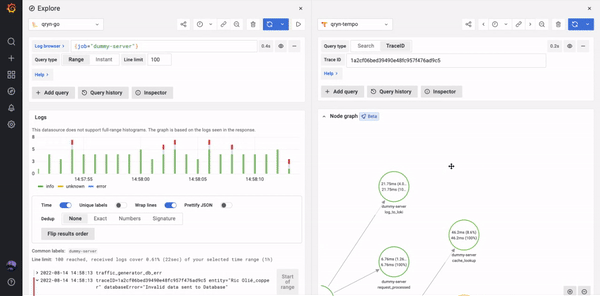
TLDR; Bring your existing data Agent or pipe data from your current solution.
⚡ It's FAST
qryn is extremely fast and can ingest and process millions of data streams per second on relatively modest hardware resources. The stack was designed as a smart, light overlay over ClickHouse, an incredibly fast column-oriented OLAP database powering qryn's ingestion and search capabilities. Behind the scenes, every supported query language gets transpiled into efficient and sophisticated ClickHouse SQL queries.
INSERTING 500k/s/thread
Deploying on the cloud? qryn is natively compatible with any ClickHouse as-a-service provider our there such as Altinity, DoubleCloud, Gigapipe and many others.
🚀 Start using qryn today!
To get started, follow the easy instructions available at qryn.dev
For a full blown demo w/ sample data, begin with our polyglot docker repository.
Conclusion
qryn is a polyglot observability framework that makes it easy to use your favorite monitoring tools with any language or platform.
It's not requiring custom agents and formats, and delivers a complete stack you can plug into from your existing logging infrastructure, providing metrics and tracing to your favorite tools, out of the box.
qryn is available as OSS + Cloud versions and runs on Kubernetes, docker as well as any other modern Linux environment - so it doesn't matter if your app lives on AWS or Google cloud or on your dedicated infrastructure - you can start qryn right away!
❤️ Made by Humans
This project is made by humans. Dig it? Please consider sponsoring our team!

" When you can rely on things that the public already knows,
you're dealing with Pop.” ― Nuno Roque 💡